搜索到
16
篇与
的结果
-
 一个比较好用的python logger脚本 在需要添加日志的python文件中#注入 from modules.logger import get_logger logger = get_logger(__name__,"sql.log") #日志写入 logger.warning("%s的%s的最大值为None,返回默认的None",\ table_name,select_columns)""" 日志模块 """ def get_logger(name, log_name="wr.log", debug_mode=True, notification=True): """ 获取日志对象 :param name: 日志名称 填入 "__name__" :param log_name: 日志文件名称 usage: from modules.logger import get_logger logger = get_logger(__name__) logger.info("这是一个info 的log信息有%s,%s等信息", param1, param2,) """ # 获取log文件路径 main__working_dir = getattr(sys, "_MEIPASS", os.getcwd()) log_dir = os.path.join(main__working_dir, "logs") if not os.path.exists(log_dir): os.makedirs(log_dir) # 创建logger logger = logging.getLogger(name) # 设置日志格式 formatter = logging.Formatter( "%(asctime)s - %(levelname)s -" "[%(filename)s:%(lineno)d] -%(funcName)s - %(message)s" ) # 创建一个滚动文件处理器,每个日志文件最大大小为5M,保存5个旧日志文件 rf_handler = RotatingFileHandler( os.path.join(log_dir, log_name), maxBytes=5 * 1024 * 1024, backupCount=5, encoding="utf-8", ) rf_handler.setFormatter(formatter) logger.addHandler(rf_handler) if debug_mode: # 如果debug模式打开,则输出到控制台 print("Debug mode is on, log will be output to console.") logger.setLevel(logging.DEBUG) console_handler = logging.StreamHandler() console_handler.setFormatter(formatter) logger.addHandler(console_handler) elif notification: # 如果错误类型是error,则发送邮件通知管理员 notificatio_handler = NotificationHandler() notificatio_handler.setFormatter(formatter) logger.addHandler(notificatio_handler) return logger class NotificationHandler(logging.Handler): """信息通知""" def emit(self, record): if record.levelno >= logging.ERROR: error_message = self.format(record) dingrobot(error_message) def dingrobot( msg: list | str = "当你看到这个说明你没有填写msg", msgtype="text", access_token="access_token", safe_word=">-<", ) -> bool: """ 钉钉机器人推送 :param access_token: 钉钉机器人的access_token :param msg: 推送消息,可以是字符串或列表,列表第一个元素为标题,第二个元素为内容 :param msgtype: 推送消息类型,可选值为text或markdown :return: bool """ requests = importlib.import_module("requests") json = importlib.import_module("json") match msgtype: case "text": data = {"text": {"content": f"{safe_word}---{msg}"}, "msgtype": "text"} case "markdown": data = { "markdown": {"text": f"{safe_word}---{msg[1]}", "title": msg[0]}, "msgtype": "markdown", } headers = {"Content-Type": "application/json"} rebot_url = f"https://oapi.dingtalk.com/robot/send?access_token={access_token}" robot = requests.post( url=rebot_url, data=json.dumps(data), headers=headers, timeout=5 ) if robot.status_code != 200: return False return True if __name__ == "__main__": LOGGER = get_logger(__name__) LOGGER.debug("这是一个ERROR 的log信息有%s,%s等信息", "param1", "param2")
一个比较好用的python logger脚本 在需要添加日志的python文件中#注入 from modules.logger import get_logger logger = get_logger(__name__,"sql.log") #日志写入 logger.warning("%s的%s的最大值为None,返回默认的None",\ table_name,select_columns)""" 日志模块 """ def get_logger(name, log_name="wr.log", debug_mode=True, notification=True): """ 获取日志对象 :param name: 日志名称 填入 "__name__" :param log_name: 日志文件名称 usage: from modules.logger import get_logger logger = get_logger(__name__) logger.info("这是一个info 的log信息有%s,%s等信息", param1, param2,) """ # 获取log文件路径 main__working_dir = getattr(sys, "_MEIPASS", os.getcwd()) log_dir = os.path.join(main__working_dir, "logs") if not os.path.exists(log_dir): os.makedirs(log_dir) # 创建logger logger = logging.getLogger(name) # 设置日志格式 formatter = logging.Formatter( "%(asctime)s - %(levelname)s -" "[%(filename)s:%(lineno)d] -%(funcName)s - %(message)s" ) # 创建一个滚动文件处理器,每个日志文件最大大小为5M,保存5个旧日志文件 rf_handler = RotatingFileHandler( os.path.join(log_dir, log_name), maxBytes=5 * 1024 * 1024, backupCount=5, encoding="utf-8", ) rf_handler.setFormatter(formatter) logger.addHandler(rf_handler) if debug_mode: # 如果debug模式打开,则输出到控制台 print("Debug mode is on, log will be output to console.") logger.setLevel(logging.DEBUG) console_handler = logging.StreamHandler() console_handler.setFormatter(formatter) logger.addHandler(console_handler) elif notification: # 如果错误类型是error,则发送邮件通知管理员 notificatio_handler = NotificationHandler() notificatio_handler.setFormatter(formatter) logger.addHandler(notificatio_handler) return logger class NotificationHandler(logging.Handler): """信息通知""" def emit(self, record): if record.levelno >= logging.ERROR: error_message = self.format(record) dingrobot(error_message) def dingrobot( msg: list | str = "当你看到这个说明你没有填写msg", msgtype="text", access_token="access_token", safe_word=">-<", ) -> bool: """ 钉钉机器人推送 :param access_token: 钉钉机器人的access_token :param msg: 推送消息,可以是字符串或列表,列表第一个元素为标题,第二个元素为内容 :param msgtype: 推送消息类型,可选值为text或markdown :return: bool """ requests = importlib.import_module("requests") json = importlib.import_module("json") match msgtype: case "text": data = {"text": {"content": f"{safe_word}---{msg}"}, "msgtype": "text"} case "markdown": data = { "markdown": {"text": f"{safe_word}---{msg[1]}", "title": msg[0]}, "msgtype": "markdown", } headers = {"Content-Type": "application/json"} rebot_url = f"https://oapi.dingtalk.com/robot/send?access_token={access_token}" robot = requests.post( url=rebot_url, data=json.dumps(data), headers=headers, timeout=5 ) if robot.status_code != 200: return False return True if __name__ == "__main__": LOGGER = get_logger(__name__) LOGGER.debug("这是一个ERROR 的log信息有%s,%s等信息", "param1", "param2") -
多个表格在不同下文件夹下面汇总到同一个表不同工作簿的方法 """ #主文件夹 #sheet1name #name1.xlsx #name2.xlsx #name3.xlsx #sheet2name #name1.xlsx #name2.xlsx #name3.xlsx #workbook sheet1name sheet2name 这个工具的作用就是 将和sheetname名字相同的1个文件夹中的所有的excel文件合并成一个pandas件,并将数据写入到对应的sheet中。 """ import os import xlwings as xw import pandas as pd path = f"{os.path.split(os.path.realpath(__file__))[0]}/" def readsheet_to_sheet(workbook, sheetname): '''读取sheetname对应的文件夹中的所有excel文件,并将数据合并到一个pandas数据框中''' folder_path = path + sheetname all_df = pd.DataFrame() for filename in os.listdir(folder_path): if filename.endswith('.xlsx'): file_path = os.path.join(folder_path, filename) print(f"Reading sheets from {file_path}:") with xw.Book(file_path) as wb: for sheet in wb.sheets: # 读取工作表数据并跳过第一行 df = sheet.used_range.options(pd.DataFrame, index=False, header=1).value # 打印工作表名称和数据 print(f"\nSheet: {sheet.name}") print(df) all_df = pd.concat([all_df,df],ignore_index=True) workbook.sheets[sheetname].range("A2").options(header = False , index = False).value = all_df def main(book_name): ''' 打开excel文件''' wb1 = xw.books(book_name) ########## #这里做了切片, 因为我前面2个工作表是不需要收集的 shop_list = [x for x in wb1.sheet_names][3:] for i in shop_list: readsheet_to_sheet(workbook=wb1,sheetname=i) if __name__ == "__main__": main("file_name.xlsx") 5月7日更新""" #主文件夹 #sheet1name #name1.xlsx #name2.xlsx #name3.xlsx #sheet2name #name1.xlsx #name2.xlsx #name3.xlsx #workbook sheet1name sheet2name 这个工具的作用就是 将和sheetname名字相同的1个文件夹中的所有的excel文件合并成一个pandas件,并将数据写入到对应的sheet中。 """ import os import pandas as pd import xlwings as xw path = f"{os.path.split(os.path.realpath(__file__))[0]}/" def readsheet_to_sheet(sheetname): """读取sheetname对应的文件夹中的所有excel文件,并将数据合并到一个pandas数据框中""" folder_path = path + sheetname all_df = pd.DataFrame() for filename in os.listdir(folder_path): if filename.endswith(".csv"): file_path = os.path.join(folder_path, filename) print(f"Reading sheets from {file_path}:") with xw.Book(file_path) as wb: for sheet in wb.sheets: # 读取工作表数据并跳过第一行 df = sheet.used_range.options( pd.DataFrame, index=False, header=1 ).value # 打印工作表名称和数据 print(f"\nSheet: {sheet.name}") all_df = pd.concat([all_df, df], ignore_index=True) all_df["店铺名称"] = sheetname # all_df["月份"] = pd.to_datetime(df["订单下单时间"]) return all_df # workbook.sheets[sheetname].range("A2").options(header = False , index = False).value = all_df def main(): """打开excel文件""" wb = xw.books.active shop_list = [ "JD-技嘉旗舰店", "JD-技嘉DIY旗舰店", "JD-AMD旗舰店", "JD-AORUS旗舰店", "JD-嘉志硕", "JD-图迈", "JD-优卡", "JD-XPG旗舰店", "JD-七彩虹旗舰店", ] df = pd.DataFrame() for i in shop_list: df = pd.concat([df, readsheet_to_sheet(i)], ignore_index=True) print(df) wb.sheets["综合优惠信息"].tables["综合优惠信息"].update(df, index=False) if __name__ == "__main__": main()
-
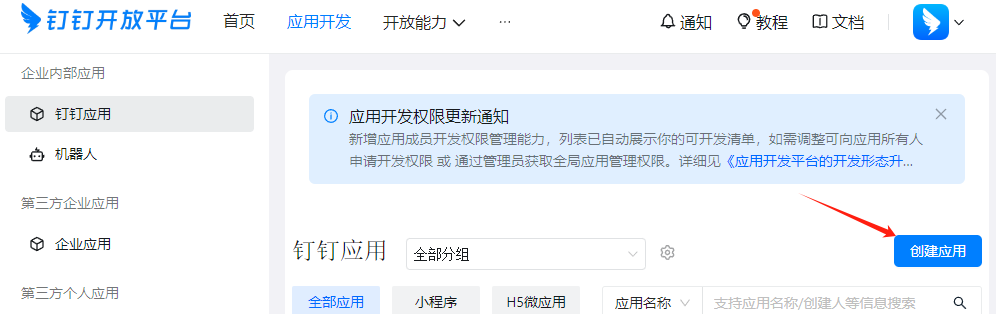
记录一下python 写入钉钉在线表格的过程 {timeline}{timeline-item color="#19be6b"} 2024年11月17日更新{/timeline-item}{/timeline}成为开发者自己创建一个企业, 或者让你所在的公司给予你的账号一个权限 钉钉开发者后台登录创建一个应用如图,这里只需要Client ID (原 AppKey 和 SuiteKey)Client Secret (原 AppSecret 和 SuiteSecret)这两个东西 获取 access_token 然后还需要一个userid 提供的operatorId:表示待办事项的操作者的ID,是一个唯一的标识符。这个可以在钉钉提供的API接口直接获取到, 目前来看是不会变化的后面就是源码了import requests import json import pandas as pd import datetime class Ding(): """ 钉钉表格推送数据 文档信息 https://open.dingtalk.com/document/orgapp/update-cell-properties """ def __init__(self,appkey,appsecret,operatorid,sheetid): #获取access_token access_token = requests.get(f"https://oapi.dingtalk.com/gettoken?"\ f"appkey={appkey}&appsecret={appsecret}",\ timeout=5).json()["access_token"] #设置基础的请求头 self.default_settings = { 'headers':{'Host':'api.dingtalk.com', 'x-acs-dingtalk-access-token':access_token, 'Content-Type':'application/json'}, 'verify': False, 'timeout': 20} self.primary_domain = "https://api.dingtalk.com/v1.0/doc/workbooks/" self.operatorid = operatorid self.sheetid= sheetid def get(self,sheetname,get_range): """ 单独获取单元格内容 """ url = f"{self.primary_domain}{self.sheetid}"\ f"/sheets/{sheetname}/ranges/{get_range}"\ f"?operatorId={self.operatorid}" res = requests.get(url,**self.default_settings) return res.json()["displayValues"] def put(self,sheetname,wt_range,content): """ 单独写入单元格内容 """ url = f"{self.primary_domain}{self.sheetid}"\ f"/sheets/{sheetname}/ranges/{wt_range}"\ f"?operatorId={self.operatorid}" json1 = {"values" : [content]} res = requests.put(url,data=json.dumps(json1),**self.default_settings) if res.status_code != 200: print("钉钉表格推送失败") print(res.text) def clear(self,sheetname,wt_range): """ 清空单元格全部 """ url = f"{self.primary_domain}{self.sheetid}"\ f"/sheets/{sheetname}/ranges/{wt_range}/clear"\ f"?operatorId={self.operatorid}" res = requests.post(url,**self.default_settings) if res.status_code != 200: print("钉钉表格推送失败") print(res.text) def cleardata(self,sheetname,wt_range): """ 清空单元格数据 """ url = f"{self.primary_domain}{self.sheetid}"\ f"/sheets/{sheetname}/ranges/{wt_range}/clearData"\ f"?operatorId={self.operatorid}" res = requests.post(url,**self.default_settings) if res.status_code != 200: print("钉钉表格推送失败") print(res.text) def put_df_to_ding(self,sheetname:str,df_data:pd.DataFrame,wt_range:str,is_mater_head=False): """ 写入dataframe数据到 钉钉表格中 """ letters = list(string.ascii_uppercase) + [letters1 + letters2 \ for letters1 in string.ascii_uppercase\ for letters2 in string.ascii_uppercase] # 写入表格前面的字母 wt_range_latter = ''.join([char for char in wt_range if char.isalpha()]) # 写入表格后面的数字 wt_range_numberr = int(''.join([char for char in wt_range if char.isdigit()])) # 写入表格的宽度 df_width = df_data.shape[1] # 写入表格的起始和结束位置的字母 left_letter = wt_range_latter right_letter = letters[letters.index(left_letter)+df_width-1] def meterhead(df_data:pd.DataFrame): """ 写入表头 """ url = f"{self.primary_domain}{self.sheetid}"\ f"/sheets/{sheetname}/ranges/"\ f"{left_letter}{wt_range_numberr}:{right_letter}{wt_range_numberr}"\ f"?operatorId={self.operatorid}" input_data = {"values" : [df_data.columns.tolist()]} res = requests.put(url,data=json.dumps(input_data),**self.default_settings) if res.status_code != 200: print("钉钉表格推送失败") print(res.text) def put_data(df_data:pd.DataFrame,start_index,end_index): """ 写入表格数据, """ #如果需要写入表头 就需要往下移动一格 就将offset设置为1 offset = 1 if is_mater_head else 0 url = f"{self.primary_domain}{self.sheetid}"\ f"/sheets/{sheetname}/ranges/"\ f"{left_letter}{wt_range_numberr+start_index+offset}:"\ f"{right_letter}{wt_range_numberr+end_index+offset}"\ f"?operatorId={self.operatorid}" input_data = {"values" :\ df_data.astype("str").iloc[start_index:end_index+1].values.tolist()} res = requests.put(url,data=json.dumps(input_data),**self.default_settings) if res.status_code != 200: print("钉钉表格推送失败") print(res.text) def cycle(df:pd.DataFrame): df_height = df.shape[0] width_per_cycle = 1000 num_segments = df_height // width_per_cycle for i in range(num_segments): start = i * width_per_cycle end = (i + 1) * width_per_cycle-1 put_data(df,start,end) if df_height % width_per_cycle != 0: start = num_segments * width_per_cycle end = df_height-1 put_data(df,start,end) if is_mater_head: meterhead(df_data) cycle(df_data) if __name__ == "__main__": DING = Ding(appkey = "appkey", appsecret ="appsecret", operatorid = "operatorid", sheetid= "表格ID",) df_test = pd.DataFrame({"A": [x for x in range(1,1002)], "B": [x for x in range(1,1002)]}) DING.put_df_to_ding(sheetname="Sheet1",df_data=df_test,wt_range="A15",is_mater_head=False) DING.cleardata(sheetname="Sheet1",wt_range="A15:C15")
-
-
.png?key=905325)
.png?key=679559)
.png?key=714755)